날씨가 많이 풀렸다. 역시 글을 시작하기 마땅한 소재가 없을 때는 날씨 이야기가 최고다. 이번 챕터는 생각보다 정리할 내용이 많았다. 그래서 작은 단위로 쪼개서 정리를 했으나 사람에 따라서 연결이 매끄럽지 않게 느껴질 수도 있을 것 같다. 그럼 좋은 날씨만큼 좋은 글이 되길 바라며 시작해보겠다.
HDD는 매우 느리기 때문에 빠른 친구인 캐시를 활용하여 속도를 확보하자!
아래는 3장에서 중요하다고 생각된 내용이다. (항상 악필인 것에 대해 미안하게 생각한다)

전체적인 내용 중 꼭 알고 넘어가야하는 부분만 정리했다. 특히 공유메모리부분(SGA, PGA)는 중요한 개념이라 꼭 알고 넘어가길 바라며 빨간별을 넣었다.
캐시가 무엇이며, 왜 필요한가?
앞선 1장을 통해서 ‘HDD는 매우 느리고 답답하기 때문에 I/O는 꼭 필요하지만 최소화 하자!’라는 결론을 냈었다. 캐시는 이런 HDD와의 I/O를 최소한으로 줄여주는 편리한 개념이다.
그럼 캐시란 무엇인가? 책에서는 작업장 혹은 작업대에 비유를 했다. 내가 화가라고 가정을 하자.(상상은 누구나 가능하니깐ㅋㅋ) 밑그림을 그리기 위해 2HB연필로 스케치를 한다. 중간에 그림에서 수정할 사항이 있어 지우개를 사용할 떄, 연필을 서랍장에 넣고 지우개를 꺼내는 경우는 없을 것이다. 그냥 연필과 지우개 모두 책상에 올려놓고 밑그림을 그리는 동안 자유롭게 바꿔쓰고 작업이 끝나면 정리를 하는 것이 효율적이기 때문이다.
캐시는 이러한 도구를 올려놓는 공간이다. 클라이언트가 요청한 SQL에 대한 결과를 캐시에 저장해 놓는다. 후에 같은 요청이 들어오면 먼저 캐시에 결과값이 있는지 확인하고 존재한다면 HDD를 거치지 않고 결과를 돌려준다.
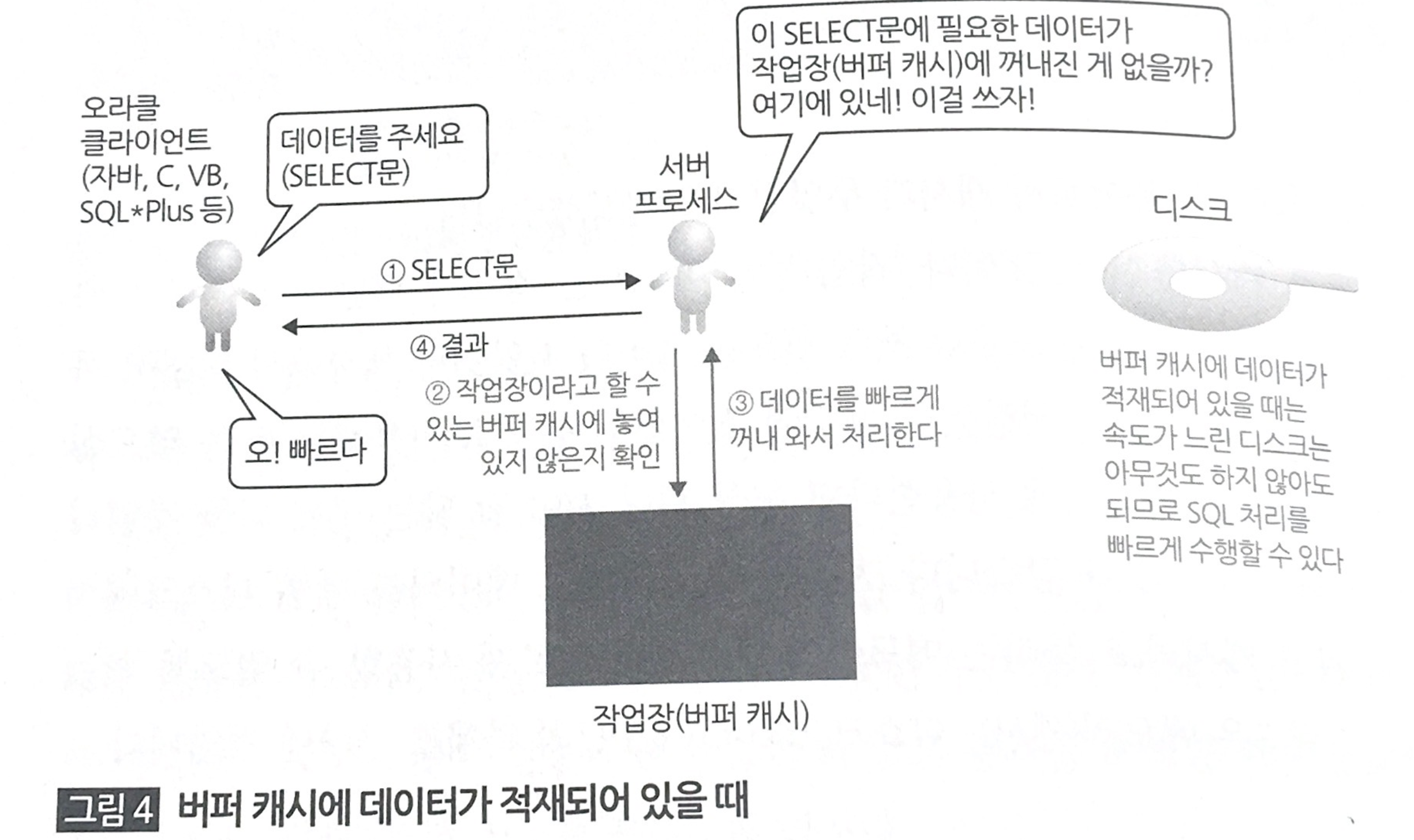
캐시가 크고 많은 데이터를 담아 둘 수 있다면 HDD와의 I/O를 최소화 할 수 있어 속도를 크게 개선 시킬 수 있다.
오라클의 데이터 관리 단위, Block
블록은 다이소에서 파는 정리상자와 비슷하다. 정리상자 안에 연필 한 자루가 있던, 과자로 가득 차있던 차지하는 부피는 동일하다. 같은 원리로 블록은 데이터의 존재유무와 상관없이 동일한 크기로 관리된다.
크게는 Header 영역와 Free Area + Row Data로 구분하지만 디테일하게는 Table Directory, Row Directory 등이 있다. 책에서는 간단하게 구분하므로 저 역시 책을 따라가겠다.
헤더 영역에는 블록에 대한 정보를 담는다. 주소값이라던가 세그먼트 타입 등이 그것이다. Free Area는 블록의 데이터를 담고 남은 공간을 의미한다. 정리상자에 연필 한자루만 담는다면 안에 남는 여유공간이 Free Area가 되고 연필이 Row Data가 되는 것이다.
데이터가 입력되면 Free Area가 점점 줄어들고 Row Data가 쌓이가 된다. 만약 데이터의 삭제가 발생된다면 기존에 있던 Row Data를 지우지만 해당 공간에는 새로운 데이터를 채우지 않는다.(별도의 명령을 통해 채우도록 할 수도 있다)
테이블 뿐만 아니라 인덱스도 블록으로 구성되어 있으니 오라클에 대해 이해하기 위해 꼭 필요한 개념이다.
공유메모리
모든 프로세스마다 캐시를 갖게 되면 낭비가 발생하고, 다른 프로세스가 변경한 데이터를 확인 할 수 없는 등의 문제가 발생한다. 따라서 오라클 내에 모든 프로세스가 공유할 수 있는 메모리를 만들어 다같이 사용한다.
이를 공유메모리 혹은 SGA(System Global Area)라고 한다. 반대로 각 프로세스만 사용하는 메모리도 있는데 이는 PGA(Program Global Area)라 부른다. 이 개념은 오라클의 구조에 있어 중요한 부분이니 꼭 숙지를 하고 넘어가야한다.
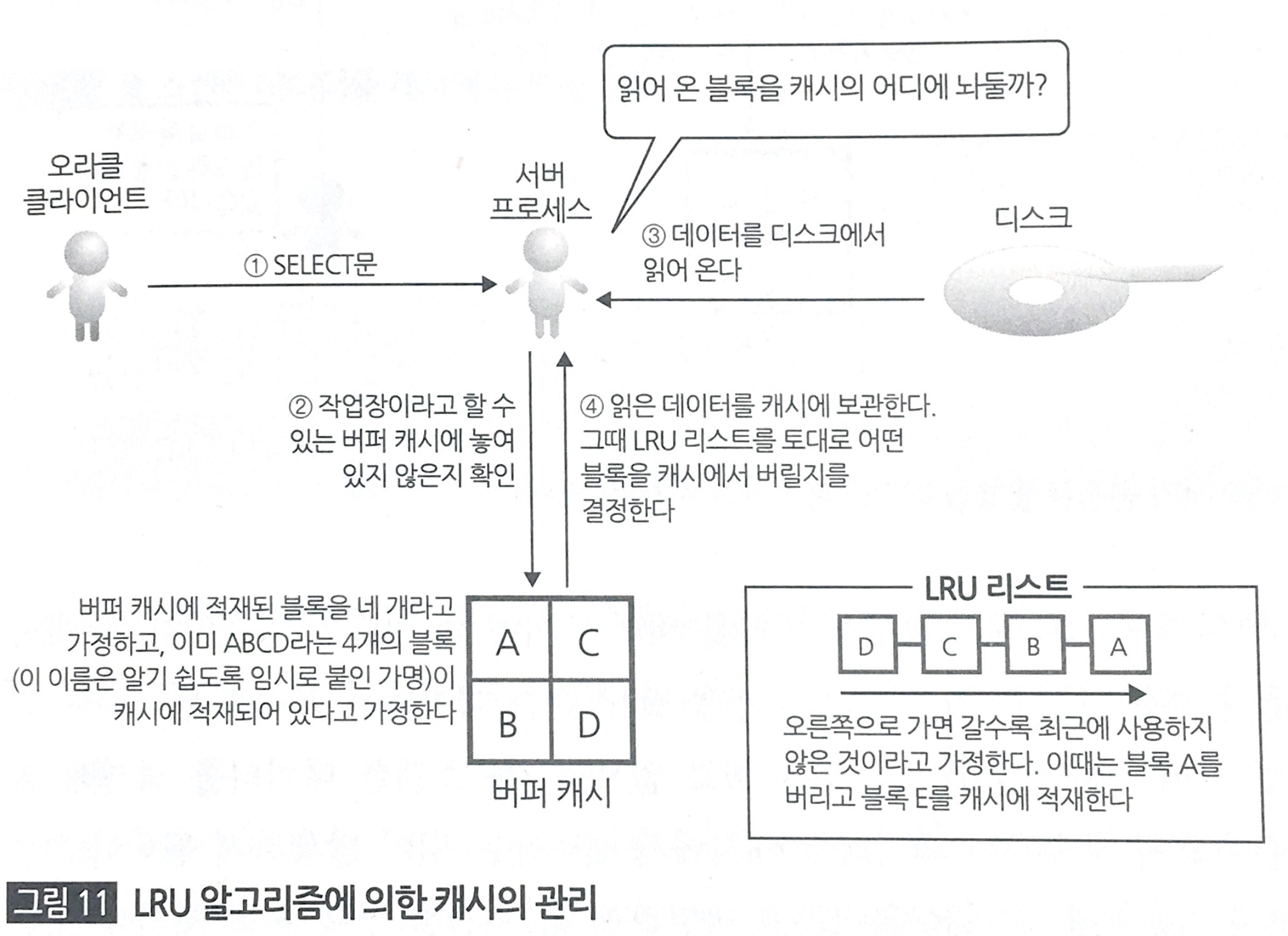
캐시를 정리하는 LRU 알고리즘
LRU알고리즘의 핵심은 ‘최근에 사용하지 않는 데이터부터 캐시에서 버린다’ 이다. 캐시메모리는 제한적이기 때문에 불필요한 데이터를 지우고 자주 사용하는 데이터로 채워놔야한다.
여기에 적합한 알고리즘을 잘 선택했다고 생각이 든다. 참고적으로 Full Scan한 데이터는 캐시에 저장하지 않는다고 한다. 자주 일어나는 일도 아닐 뿐더러 Full Scan 데이터가 캐시에 자리잡으면 정작 필요한 데이터를 담아둘 공간이 없기 때문이다.
마치며
이번 챕터는 큰 타이틀을 중심으로 토막토막 정리하였다. 연관성이 떨어져 보이나 다들 캐시라는 공통된 주제에 포함되어 있다는 것을 안다면 자연스럽게 연결될 것이다.
캐시가 주는 장점에 대해 길게 설명해봤는데 그럼 단점은 무엇일까? 책에서는 성능 테스트시에 유의하기를 충고한다.
첫 조회에 속도가 느렸지만 두번, 세번… 연이은 조회에선 빠른 속도가 나온다고 첫 조회의 지연을 가볍게 넘기면 안된다고 지적한다. 캐시로 인한 빠른 조회속도가 테스트시에는 독이 될 수 있다는 말이다.
글을 하나 쓰고나니 배가 고프다. 이제 밥먹으러 가야겠다 ㅎㅎ 다들 따뜻한 봄을 즐기길 바란다 :)