리두와 언두를 왜 배워야 하는가?
트랜잭션은 “ACID” 라는 특성을 만족합니다. 이 특성을 만족시키기 위해 리두(redo)와 언두(undo)는 빠질 수 없으므로 이들을 통해 트랜잭션의 특성을 깊게 이해할 수 있습니다. 우선 ACID가 무엇인지 살펴보겠습니다.
- Atomicity(원자성)
- Consistency(일관성)
- Isolation(고립성)
- Durabliity(지속성)
위 4종류의 특성이 만족해야만 비로소 트랜잭션이라 할 수 있습니다. 조금 더 세부적으로 살펴보겠습니다.
Atomicity(원자성)
한 문장으로 이야기 하면 ‘All or nothing’ 입니다. 즉, 데이터가 변경된다면 전부 완료가 되거나 모두 실패해야한다는 뜻입니다. 예를 들어 회원가입할 때, 회원정보를 DB에 입력하는 것이 하나의 트랜잭션이라면 이름, 주소를 잘 입력했어도 휴대폰번호에 문자가 있어 오류가 발생했다면 이름과 주소 역시 입력되지 말아야 합니다.
따라서 원자성은 데이터 변경의 최소단위라고 할 수 있습니다.
Consistency(일관성)
데이터 모델 간의 일관성이 유지되어야 한다는 의미입니다. EMP 테이블과 SALARY 테이블이 EMP_ID로 연결되어 있을 때, EMP_ID의 타입이 NUMBER에서 VARCHAR2로 변경 된다면 두 테이블 모두 동일하게 변경된 내용이 적용되어야 합니다.
Isolation(고립성)
트랜잭션 간 서로 독립적이여야 합니다. 회원가입 트랜잭션이 게시판 글쓰기 트랜잭션과 동시에 진행된다고 해서 회원가입 트랜잭션 결과에 영향이 있어서는 안되는 것 처럼 말입니다. 단, DBMS에 따라 고립의 레벨을 선택할 수 있습니다.
Durability(지속성)
커밋한 트랜잭션은 장애가 발생하더라도 데이터는 반드시 복구(지속)되어야 한다는 의미입니다. 커밋이 완료된 트랜잭션에 대해 신뢰할 수 있는 기반이 됩니다.
지속성을 구현하기 위해서는
먼저 간단한 질문을 해보겠습니다.
“커밋한 데이터를 즉시 디스크에 기록하고 이력을 남겨둔다면 데이터의 지속성을 지킬 수 있지 않을까요?”
위 질문에 대해 전 “그렇다” 라고 생각합니다. 커밋하기 전에 이력을 남기고 디스크에 기록한다면 어떤 시점에 장애가 발생해도 지속성을 지킬 수 있다고 생각이 듭니다.
하지만 책에서는 디스크의 특성을 들어 위 방법의 단점을 이야기합니다. 디스크 I/O는 대부분의 시간을 트랙을 찾는데 사용합니다. 그래서 변경이 있을 때 마다 디스크에 기록하면 커밋에 많은 시간을 소요하게 됩니다. 따라서 오라클은 이력을 보다 적극적으로 사용하여 성능과 지속성이라는 두 마리 토끼를 모두 잡는 노력을 합니다.
어떤 방법으로 구현하는지는 아래 리두의 아키텍처에서 자세히 설명하도록 하겠습니다.
리두와 언두의 개념
데이터를 복구한다는 것은 두 가지 입장에서 생각해 볼 수 있습니다. 하나는 데이터 변경이 일어났으나 과거의 데이터로 돌리는 경우이고, 다른 하나는 데이터 변경이 일어났으나 반영이 되지 않아 다시 적용시키는 경우입니다. 간단한 예를 들어보겠습니다.
- 새해가 되어 기존 직원들의 연봉을 올려야 하니 SALARY 테이블의 연봉을 모두 500만원씩 올리려고 했는데, 실수로 5000만원씩 올리고 커밋이 되었다.
- 새해가 되어 기존 직원들의 연봉을 올려야 하니 SALARY 테이블의 연봉을 모두 500만원씩 올리려고 했는데, 반영되지 않아 1월달 급여가 작년도 기준으로 책정되어 있다.
1번 상황을 롤백, 2번 상황을 롤포워드 라고 하며 롤백에는 언두 로그가, 롤포워드에는 리두 로그가 각각 필요합니다.
추가적으로 오라클은 시간의 흐름을 SCN(System Change Number)라는 개념으로 관리하고 있습니다. 따라서 SCN과 현재 데이터 정보, 리두, 언두 정보를 기반으로 데이터의 복구가 진행됩니다.
리두의 아키텍처
데이터의 변경은 캐시 위에서 이루어 집니다. 동시에 리두 로그 데이터가 생성되면 캐시 안의 리두로그버퍼에 쌓고 커밋이 되지 않았어도 블록의 데이터 변경이 일어납니다. 이는 지속성을 구현하는 방법이며 동시에, 성능의 단점도 개선할 수 있습니다. 책의 그림을 먼저 보겠습니다.
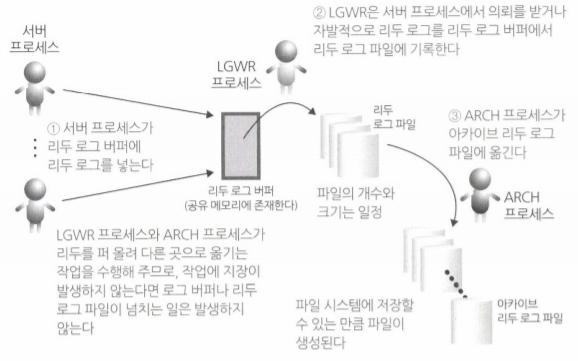
우선 LGWR, ARCH, 아카이브 리두 로그 파일 등 낯선 용어에 대해 설명하겠습니다. LGWR는 리두 로그를 디스크에 기록하는 역할을 합니다. ARCH 프로세스는 리두 로그 파일이 가득 차기 전에 비교적 장기간 보관할 수 있는 아카이브 리두 로그 파일에 옮기는 역할을 합니다. 마지막으로 아카이브 리두 로그 파일은 리두 로그를 장기간 보관하기 위한 파일입니다.
위 내용을 바탕으로 리두 아키텍처를 요약해본다면 데이터의 변경이 일어나면 캐시 내 리두 로그 버퍼에 쌓입니다. 리두 로그 버퍼에 특정 조건이 만족하면 LGWR가 디스크 내의 리두 로그 파일에 로그를 쌓습니다. 리두 로그 파일은 캐시보다 안전하지만 방대한 양의 로그를 쌓기에는 적합하지 않습니다. 따라서 장기간 보관할 수 있는 아카이브 리두 로그 파일로 데이터를 옮겨야 합니다. 이 작업은 ARCH 프로세스가 담당하여 진행합니다.
단, 성능의 단점을 개선하기 위해 위 프로세스는 커밋과 연동하여 진행하지 않습니다.
언두의 아키텍처
과거의 상태로 데이터를 돌리기 위한 언두는 수동과 자동이 있습니다. 자동 언두가 편리하면서 자주 사용되므로 이를 중심으로 기술하겠습니다.
데이터가 변경되면 언두 정보가 생성되어 세그먼트에 보관됩니다. 해당 세그먼트를 관리하는 테이블 스페이스를 언두 테이블 스페이라고 합니다. 언두 테이블 스페이스는 다른 테이블 스페이스와 달리 구조가 독특합니다. 링 버퍼 형태로 순차적으로 데이터를 쌓는데 링이 가득 차면 가장 처음 입력된 데이터의 버퍼에 덮어씌웁니다. 다만, 커밋하지 않은 데이터는 덮지 않습니다.
위와 같은 방식으로 언두는 과거의 데이터로 돌아갈 수 있게 됩니다.
요약
- 리두는 오래된 데이터를 최신 데이터로 만들기 위해 존재합ㄴ다.
- 언두는 최신 데이터를 오래된 데이터로 만들기 위해 존재한다.
- 읽기 일관성을 위해 언두를 사용한다.
- ORA-1555 오류가 발생하면 우선적으로 undo_retention이나 언두 테이블 스페이스 크기를 튜닝할 것을 검토한다.
- 장비에 장애가 발생하거나 인스턴스가 비정상 종료했을 경우, 리두와 언두를 사용해 데이터를 복구하고 커밋하지 않은 데이터의 롤백을 수행한다.
오늘도 어김없이 감사합니다 ;)