일주일에 한번씩 작성하기로 했는데 지난주에 못써서 이번주에 첫 포스팅을 하게 되었다 : (
우선 개별적으로 1장을 읽으며 정리한 내용을 토대로 결론을 내리자면 다음과 같다.
디스크는 느리다!

개발자 답게 개발스러운 필기다 : )
흔히 SSD(흔히 스스디라고 표현하는 저장장치)를 한 번이라도 사용한 사람은 HDD(a.k.a 하드디스크)를 쓰기 힘들다고 한다. 왜냐하면 느리기 때문이다.
데이터베이스를 설명하다가 왜 뜬금없이 HDD가 느리다고 디스하는지 궁금할 것이다. HDD가 느리다고 생각하는건 사람만 그런 것이 아니라 데이터베이스 입장에서도 마찬가지기 때문이다.
그나마 우리는 SSD와 HDD를 비교하지만 데이터베이스는 메모리(물리적으로는 RAM을 말한다)와 HDD를 비교하기 때문에 더더욱 HDD의 속도에 불만을 갖고 사용하기 싫어한다.
아래 그림을 보자
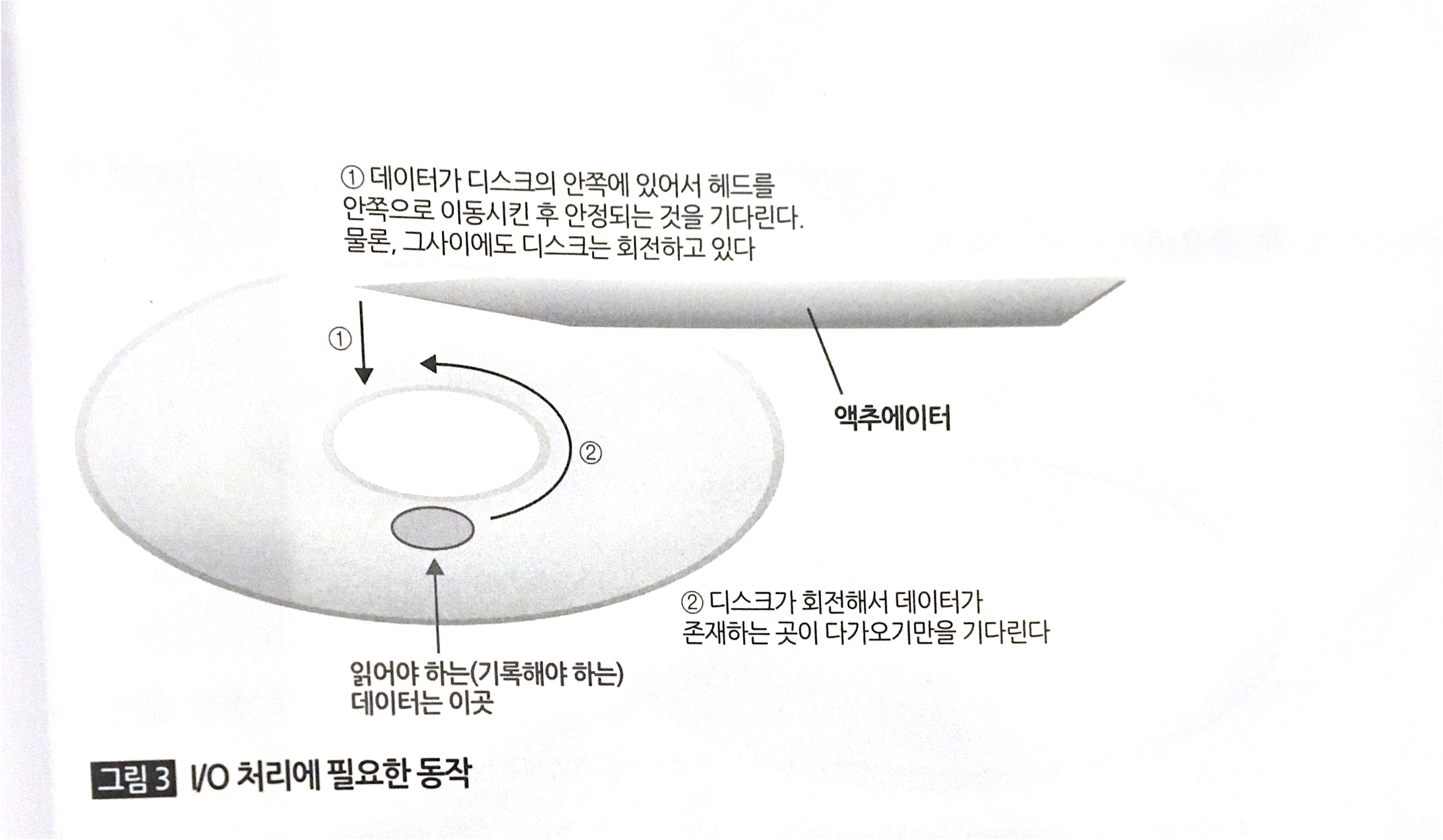
고개를 왼쪽으로 10도만 돌리고 보세요 ㅎㅎ
HDD는 동그란 판이 돌면서 의료기기처럼 생긴 엑츄에이터가 원하는 위치에 접근한 후 기록을 한다. 이렇게 엑추에이터가 디스크의 원하는 위치를 찾고 I/O를 발생시키는 것을 Seek라고 한다. 반면 메모리는 전기적인 신호로 저장을 하기 때문에 이렇게 기계가 직접 움직여서 기록하는 HDD에 비해 빠를 수 밖에 없다.
따라서, HDD의 데이터를 읽거나 쓰는 행위(이하 I/O로 표현)가 빈번하게 발생할 수록 DB의 속도는 느려지게 된다.
그렇다고 I/O없이 DB를 사용할 수는 없다. 그럼 어떻게 해야 데이터를 안전하고 빠르게 관리할 수 있을까?
이에 대한 답을 하기 전에 먼저 두 가지 개념이 필요하다
- Sequentail access (순차적 접근)
- Random access (비 순차적 접근)
시퀀셜 엑세스는 ‘처음부터 끝까지’ 라고 생각하면 좋다. 순서대로 진행하며 데이터에 접근하는 방식이기 때문이다. 반면 랜덤 엑세스는 비 연속적으로 데이터에 접근하는 방식이다. (로또처럼 확률에 맞겨 접근하는거 아니다ㅎㅎ)
잠깐 다시 위로 올라가 HDD가 동작하는 그림을 보자. 액추에이터가 디스크가 회전하는 것을 기다리다가 원하는 위치로 이동하면 데이터를 읽고 쓴다.
시퀀셜 엑세스는 연속되기 때문에 한 번의 Seek만 발생하므로 데이터의 양의 관점에서는 최대의 효율을 낼 수 있다. 과거의 카세트 테이프, CD 플레이어로 재생되던 노래를 생각해보면 쉽게 이해가 될 것이다. 내가 원하는 노래를 듣기 위해 감각적인 빨리감기(혹은 되감기)를 했던 기억이 한번쯤 있다면 나이가 있다는 것이다 ㅎㅎ
반면, 단점도 존재한다. 중간에(어쩌맨 맨 뒤에) 있는 데이터를 읽기 위해서 맨 처음부터 읽어야 하기 때문에 불필요한 I/O가 발생한다.
이를 극복하기 위해 등장한 개념이 인덱스다. 대학교에서 PPT발표를 할 때 맨 첫장에 ‘ㅇㅇㅇ 프로젝트’ 와 팀원들 이름을 적는다. 그럼 두번째 장에는 무엇을 적었을까? 바로 INDEX 이다(모두 대문자로 적는게 포인트).
얘가 걔다. 인덱스를 통해서 DB는 원하는 정보가 있는 위치(HDD상의 물리적 주소일 수도 있고, 메모리상의 주소일 수도 있다)를 빠르게 찾아갈 수 있다.
인덱스는 키와 키가 존재하는 위치가 한 쌍으로 기록되어 있다. 키는 보통 SQL의 where절에 적는 조건의 값을 의미하고 위치는 ROWID를 의미한다. 등장하기에 아직 이른감이 있지만 고난도의 SQL문 실습을 통해 인덱스를 조금 더 살펴보자.
SELECT '특징'
FROM 내정보
WHERE 이름 = '본인이름';
다들 어떤 정보가 나왔는지 궁금하다. 필자는 ‘뚠뚠한 개발자’라는 특징이 나왔다. 여러분마다 각기다른 본인의 대표특징이 생각났을 것이다. 이 SQL문을 인덱스 처리할 때는 우선 이름이 담긴 인덱스를 조사한다. 그 결과로 얻어낸 ROWID(주소)를 통해 데이터를 읽어온다. 그렇게 읽어온 데이터에는 각종 정보가 있는데 그 중 ‘특징’이라는 정보만을 보여준다.
이렇듯 인덱스는 불필요한 Full Scan을 방지하면서 동시에 속도까지 만족시킬 수 있는 편리한 개념이다.
이번엔 랜덤 엑세스에 대해 알아보자. 시퀀셜 엑세스를 비유까지 들어가며 설명했기 떄문에 여기는 가볍게 설명하고 넘어가겠다. 시퀀셜 엑세스와 반대로 디스크에서 띄엄띄엄 데이터를 읽어오는 것이 랜덤 엑세스다.
데이터 전송의 관점에서 바라보면 정말 비효율적인 방법이다.
극단적으로 비유하자면 처음부터 끝까지 엄마의 잔소리를 들으면 10분만에 다 들을 수 있는 것을 중간 중간 소심한 반항(시크를 발생)을 해서 일주일째 잔소리를 듣는 것과 비슷하다. 이만큼 엄마의 잔소리를 비효율적으로 전달받는 방법이 랜덤 엑세스이다.
이런 비유를 보고나니 랜덤 엑세스가 매우 싫어지고 부정적으로 느껴진다. 하지만 인덱스와 함께 사용한다면 다르게 느껴질 것이다. 이미 우리는 인덱스 + 랜덤 엑세스의 조합을 경험했다.
인덱스는 무엇과 무엇으로 이루어져있다고? 맞다. 키와 ROWID이다.
여기서의 ROWID가 주소, 즉, 데이터가 존재하는 실제 위치를 기록하고 있고 이를 랜덤 엑세스로 접근하게 되면 불필요한 데이터의 I/O 없이 한 번에 데이터를 가져올 수 있다.
오래 기다렸다. 데이터를 안전하고 빠르게 관리하기 위한 답을 정의해보자. 오늘 배운 내용을 기반으로 한다면 ‘I/O는 최대한 줄이되, 필요하다면 인덱스를 활용한 랜덤 엑세스를 통해 최소한의 I/O를 발생시킨다!’ 정도로 정의할 수 있겠다. 물론 이 답은 안전이라는 키워드에 대해선 답을 하지 못한다. 이는 2장에서 조금 더 자세히 다루므로 조금만 참아주길 바란다.
우리는 이번장을 통해 디스크의 I/O가 일어나는 과정, 각기 매력을 가진 두 가지의 엑세스 방법, 그리고 앞으로도 많이 마주칠 인덱스의 개념을 정리했다.
물론 책에 있는 내용 중 여기에 정리하지 않은 꿀팁도 많다. 이는 여러분이 책을 구입해서 보기 바란다. 분명 후회없는 선택이 될 것이다.